1時半に寝て6時に起きた。昨日の夜はウォーキングして (朝活あるから) すぐに寝たんで早く起きた分、朝からストレッチをしてた。今週はバタバタしていてあまりストレッチできてない。
朝活: ミクロ経済学入門の入門
[金朝ツメトギ] 2021-11-05 AM 6 金曜朝6時開催のもくもく会 で第7章の独占と寡占を読んだ。用語を次にまとめる。
- プライステイカー: 生産量を増やしたり減らしたりしても価格に影響を与えられない会社
- 完全市場: すべての会社がプライステイカーである市場
- 不完全市場: 完全市場ではない市場、プライステイカーではない会社がいる
- 独占市場: 1つの独占企業だけが存在する市場
- クルーノー寡占市場: 同じ財を生産する少数の会社の総生産量から市場の価格が決まる市場
- 寡占: 少数の企業がいる市場
- 複占: 企業が2つだけの市場
- 寡占: 少数の企業がいる市場
前に出てきた市場均衡の話から、供給量を下げると価格が上昇する。生産者余剰がが大きくなり、生産者は得をする。実際にあった事例として、2016年に石油輸出機構 (OPEC) が石油の減産に合意して価格が上昇した。2012年に豊作だった歳に値崩れが起きるのをおそれて、全国農業組合連合会は価格を上げるために農家に野菜の廃棄処分を要請した。
独占市場にいる会社は高い価格で高い利潤を得ることはできるが、やがて価格競争を仕掛けてくる新規参入者を招き、長期的な利益を低めてしまう懸念がある。一方で高品質な財を低い利潤で販売していると、新規参入者が現れずに長期的な利益を得られる可能性がある。一概にどちらが正しいとは言えない。こうした状況を端的に描く 展開型ゲーム を考えると、財を高値にするか安値にするかの思考実験ができるう。 ゲームツリー という図でこのゲームを表している。
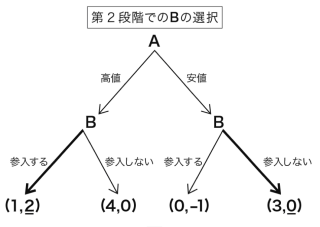
A は安値を選び、B が参入しないという選択の組み合わせは、「自分がこう選択したら相手はこう選択してくる」とプレイヤーが予想して、そのうえで自分にとって最も利潤が高まる選択をする状況を表している。これを サブゲーム完全均衡 の結果と呼ぶ。また、このような推論のやり方を 逆向き帰納法 (バックワード・インダクション) と呼ぶ。サブゲーム完全均衡の結果は逆向き帰納法により求められる。
RabbitMQ の dead letter exchange の調査
昨日の続き。RabbitMQ には exchange という概念がある。私が過去に使ったメッセージキュー (Kafka, AWS SQS) にはない概念でトピックをグルーピングしたり、メッセージのルーティングを制御する仕組みになる。普通のメッセージキューではデッドレターキューと呼ばれるものが RabbitMQ だと Dead Letter Exchanges になる。ドキュメントの概要はこんな感じ。
次のイベントが発生したときに “デッドレター” とみなす。
- consumer が basic.reject または requeue=false の basic.nack を ack で返したとき
- メッセージの TTL の期限切れになったとき
- queue の最大長さを超えてメッセージが drop されたとき
注意事項として queue の有効期限が切れても queue 内のメッセージはデッドレターとならない。
設定方法
デッドレター exchange (DLXs) は普通の exchange であり、普通に宣言して通常の種別をセットする。任意の queue に対して2通りの設定方法がある。
- クライアント: queue の引数を使って定義する
- サーバー: ポリシーを使って定義する
詳細は割愛。
ルーティング
デッドレターメッセージのルーティングは、次のどちらかで行われる。
- デッドレターの queue に routingKey が設定されていればそれを使う
- デッドレターの queue に routingKey が設定されていなければ、オリジナルのメッセージが publish されたときの routingKey を使う
例えば、foo という routingKey をもつ exchange にメッセージを publish して、そのメッセージがデッドレターになった場合、foo という routingKey をもつデッドレターの exchange に publish される。もしそのメッセージが x-dead-letter-routing-key を bar にセットした queue に届いた場合は、そのメッセージは bar という routingKey をもつデッドレター exchange に publish される。
queue に特定の routingKey が設定されていなかった場合、その queue のメッセージは、すべてオリジナルの routingKey でデッドレター化されることに注意してください。これには CC および BCC ヘッダによって追加された routingKey も含む (詳細は割愛) 。
デッドレターメッセージが循環する可能性がある。例えば、queue がデッドレター用のルーティングキーを指定せずに、デフォルトの exchange にメッセージをデッドレターした場合などに起こる。このとき同じ queue に2回届いたメッセージは no rejections in the entire cycle だった場合にドロップされる。
安全性
デッドレターメッセージは内部的に publisher confirm を行わずに re-publish される。クラスタ環境の rabbitmq でデッドレターキューを使ったとしても安全性は保証されない。メッセージはデッドレターキューの対象の queue に publish された後でオリジナルの queue からは削除される。このときに対象の queue が受け取れなければメッセージがなくなってしまう可能性がある。
デッドレターメッセージの副作用
デッドレターメッセージはヘッダーを変更する。
- exchange の名前がデッドレター exchange の名前に置き換わる
- routingKey がデッドレターキューの routingKey に置き換わる可能性がある
- ↑ が起きると、CC ヘッダーが削除される
- Sender-selected Distribution ごとに BCC ヘッダーは削除される
デッドレターの処理では x-death という名前の配列を、それぞれのデッドレタリングされたメッセージのヘッダに追加する。この配列には {queue, reason} のペアで識別される各デッドレタリングイベントのエントリが含まれる。詳細は割愛。
dapr の調査
dapr について調べた。dapr は分散システム (アプリケーション) の複雑さを解決することを目的としている。様々なミドルウェア (分散システム) とのやり取りを http/grpc の api 呼び出し経由にして、その詳細を隠蔽する。ミドルウェアの上位に抽象化レイヤーを設けて統合的なインターフェースを提供したり、それぞれのミドルウェアにおける設定や運用の面倒なことなどを簡略化してくれる。サイドカーパターンを採用しているので言語に依らず、アプリケーションに dapr のコードを書く必要もない。dapr cli をインストールして dapr init すると docker で dapr プロセスが動いて、それだけで dapr にリクエストできるようになる。使い始めの学習コストは低いし、デプロイも簡単だし、意図している目的もわかりやすい。マイクロソフト社がスポンサーしていてプロジェクトの運営も安定してそうだし、おもしろいツールだと思う。
k8s の調査
せっかくの機会なのでちゃんと勉強することにした。今日は minikube の Get Started! やっただけ。