2時に寝て6時に起きた。前日の夜にウォーキングしたせいか、よく眠れた。朝活を終えてから朝ご飯を作って食べてそのままオフィスに出社した。6時起きを日課にした方が生活のリズムがよい。夕方に眠くなって1時間ほど昼寝した。
朝活: ミクロ経済学入門の入門
【三宮.dev オンライン】リモート朝活もくもく会 で第4章の供給曲線を読んだ。需要曲線の逆からの視点なので考え方は同じで図の形が異なる。用語がいくつか出てきたのでまとめる。
- 収穫逓減 (しゅうかくていげん): 製品をより多く生産するのにかかる経費が増大していくこと
- 生産活動において2倍の生産量を生み出すには2倍以上の経費がかかる
- 費用関数: 生産量と費用との関係をあらわす
- 限界費用: 追加的に1単位生産する費用
- 3個を生産する費用は、1個目の限界費用 + 2個目の限界費用 + 3個目の限界費用
- 個数が増えるごとに費用は高くなっていく
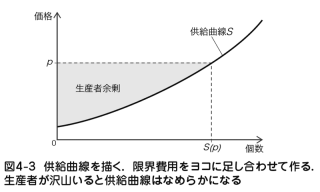
- 費用を図示するときは限界費用に分解した方が視覚的にわかりやすい
- 3個を生産する費用は、1個目の限界費用 + 2個目の限界費用 + 3個目の限界費用
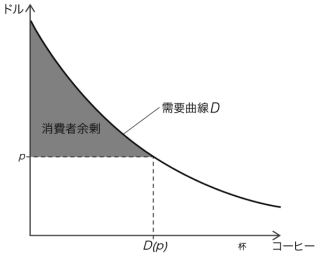
- 限界費用逓増: 生産するごとに限界費用が高まっていくこと
「逓」という漢字は「つぎつぎ」や「だんだん」という意味をもつ。
- プライステイカー: 自分の生産量が価格に影響を与えられない
- 減産により希少価値を高め価格を吊り上げる市場操作ができない
- 独占企業: プライステイカーの反対。
- 利潤: 売上 - 経費
- 最適解: 利潤を最大化する生産量
- あと1個追加して生産すると利益がマイナスになるところ
- 生産者余剰: すべての企業の利潤の和
- 供給曲線: すべての企業の限界費用をヨコに足し合わせた曲線
データ指向アプリケーションデザイン
昨日の続き。8.4 を読んで8章分散システムの問題を読み終えた。全体としても学びになったけれど、とくに 8.3 信頼性の低いクロックの節が全く開発・運用で意識したことがなかったので私にとっては学びになった。
分散システムにおいて発生する厄介な問題がある。
ネットワーク経由でパケットを送信しようとした場合、そのパケットはロストしたり、どれほど遅延するか分からない。同様に、レスポンスもロストしたり遅延したりするので、レスポンスを受け取れなかった場合には元々のメッセージが到達したかどうかも分からない
ノードのクロックは他のノードと大きくずれているかもしれない(できる限りの努力をして NTP をセットアップしたとしても)。クロックは急に進んだり戻ったりするかもしれず、たいていはクロックの誤差をうまく計る方法がないので、クロックに依存するのは危険
プロセスは処理中にいつどれほどの長さ一時停止するかもしれず(おそらくはstop-the-worldガベージコレクタのため)、他のノードから落ちていると見なされた後に自身に一時停止があったことを理解しないままに復活するかもしれない。
こういった 部分障害 が生じうるのが分散システムの特徴と言える。ソフトウェアが他のノードが関わる何かをしようとした場合、それは時おり失敗したり、ランダムに速度が落ちたり、まったくレスポンスが返されない(そして最終的にはタイムアウトする)といった可能性がある。分散システムでは、部分障害への耐性をソフトウェアに組み込み、システムの構成要素が一部破損していてもシステム全体としては機能し続けられるようにする。
フォールトに耐えるための最初のステップはフォールトを 検出 することだが、それさえも難しい。多くのシステムは、ノードに障害が生じていることを検出する正確な仕組みを持たないので、ほとんどの分散アルゴリズムはリモートノードが生きているかどうかを判断するのにタイムアウトに頼る。しかし、タイムアウトはネットワークの障害とノードの障害を区別できず、ネットワークの遅延変動のために間違ってノードがクラッシュしていると誤検知することもある。弱っているものの落ちてはいないノードは、きれいに落ちているノードよりもさらに扱いが難しくなる可能性がある。
フォールトが検出されたとして、システムがそれに耐えられるようにすることも簡単ではない。マシン間にはグローバルな変数も、共有メモリも、共通の情報やその他何らかの共有された状態もない。ノードは現在の時刻についてさえ合意できず、ましてやもっと重大なことに合意することなどできない。あるノードから他のノードへ情報を流せる唯一の方法は、その情報を信頼できないネットワークを通じて送ることだけである。重要な判断は単一のノードだけで安全に下すことができないので、他のノードの助けを得てクオラムが合意に至るようにするためのプロトコルが必要となる。
同じ操作をすれば決まって同じ結果を返してくれるような、単一コンピュータにおける理想化された数学的な完全さの中でソフトウェアを書くのに慣れていると、分散システムの雑然とした物理的な現実への移行はちょっとしたショックを伴う。一方、分散システムのエンジニアは、しばしば単一のコンピュータ上で解決できる問題を簡単なものだと見なすが、実際のところ今日では単一のコンピュータがこなせる仕事量はかなりのものになっている。単一のマシンでシンプルにことを済ませられるなら、概してそうする価値はある。
分散システムを利用する理由はスケーラビリティだけではない。耐障害性や低レイテンシ(地理的にユーザーの近くにデータを置けることによる)も同様に重要な目標であり、こういったことは単一ノードでは実現できない。本章ではネットワーク、クロック、プロセスの信頼性の低さが避けがたい自然の法則なのかも調べた。安全ではなく、クリティカルではないシステムの多くでは、高価な高信頼性よりも安価な低信頼性が選択される。また、信頼性の高いコンポーネントを前提としているスーパーコンピュータも取り上げました。スーパーコンピュータはその前提が故に、コンポーネントに障害が生じてしまった場合には完全に停止させて再起動することになる。これに対し、分散システムはサービスレベルでは中断することなくいつまでも動作し続けられる。これは、少なくとも理論上はすべてのフォールトやメンテナンスはノードレベルで処理できるためである。
お昼ご飯
気分でスーパー寄って買いものして家に帰り、お昼ご飯を作って食べた。前に適当に作った かぼちゃの煮物 がおいしかったので再挑戦してみた。今度は圧力鍋を使っていろいろ具材を入れてみた。過去に作っておいしかった料理のレシピを evernote に書いたりしていたけど、もういまは書いてないので気が向いたら日記に書くようにする。
材料
- A
- 水 900cc
- めんつゆ 100c
- 醤油 適量
- B
- かぼちゃ 1/4切れ
- なす 3個
- にんじん 2本
- 玉ねぎ 1個
- しめじ 1パック
- C
- 卵 2個
- 豆苗
- せみ餃子
作り方
- 圧力鍋に A を入れて火にかける
- B の野菜を切りながら圧力鍋に入れていく
- 圧力鍋に B をすべて入れたら圧をかける (高圧30秒)
- 圧が下がったら蓋をあけて C を入れる
- C に火が通るまで2分ほど煮込む
所感
圧力が強過ぎたのか、かぼちゃが煮汁に溶け出してしまって原形がなくなってしまった。スープとして飲んでもおいしいけれども、水を入れ過ぎたのかもしれない。肉の代わりに餃子を使ってみた。水餃子っぽくなるので焼き餃子で油使うよりヘルシーな気持ちになっておいしい。

bizpy 勉強会
Python で Slack のインテグレーションをやってみる勉強会 #1 を開催した。半年以上開催してなかったので億劫になってしまっていたけど、再開できてよかった。10名ほどが参加してくれた。用意したコンテンツを話し終えたら8時半ぐらいで時間もちょうどよかった。初参加者も数人いた。slack インテグレーションの調査も兼ねてあと2-3回は集中的にやっていきたい。